
- W klasycznym sklepie internetowym wyróżnia się następujące typy stron:
- 4 źródła błędów Architektura informacji w sklepach internetowych
- 1. Podwójne podkategorie
- 2. Podwójne strony produktów
- 3. Strony z podwójną marką
- 4. Nieistniejące strony
- streszczenie
- O autorach
Architektura informacji jest podstawą każdego witryna internetowa , Opisuje strukturę i kontekst różnych stron lub typów stron. Celem jasno skonstruowanej architektury informacji jest zapewnienie dostępności wszystkich ważnych treści dla człowieka i maszyny: Podczas gdy użytkownicy mogą łatwo znaleźć treść, którą chcą na logicznie zorganizowanej stronie internetowej i bez większego wyszukiwania, ułatwia to robotom indeksującym, treściom i ich semantycznym relacjom uchwycić. Z tego powodu już podczas planowania architektury informacji Użyteczność a integracja treści zostanie uzgodniona.
Specjalistyczny artykuł Lydii Lässig i Matthäusa Michalika
O treści
Aby móc mapować wszystkie istotne treści w najlepszy możliwy sposób na stronie internetowej, struktura informacji powinna mieć pewną stabilność, ale jednocześnie zachować elastyczność w odniesieniu do przyszłych rozszerzeń i zmian nowych lub istniejących stron.
Co należy wziąć pod uwagę podczas planowania architektury informacji? Które typy stron odgrywają rolę w strukturze?
W klasycznym sklepie internetowym wyróżnia się następujące typy stron:
- dom
- główne kategorie
- podkategorii
- produkty
- marki
- Kategorie Marki kombinacje
- Treści informacyjne / strony informacyjne
Przykład Planet Sports wygląda tak:
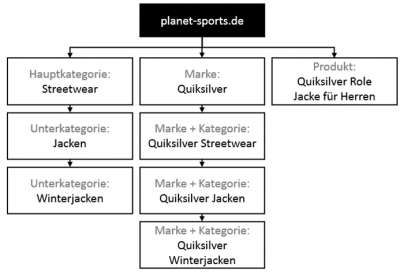
Jednak przy projektowaniu architektury informacji często włącza się błędy, które z perspektywy czasu można poprawić tylko z wielką trudnością i wysiłkiem. Jednym z powszechnych błędów wielu dużych firm jest posiadanie wielu stron na tej samej stronie Hasło Ustaw, które pochłaniają te strony. Wyszukiwarka w takich przypadkach nie wie, która ze stron powinna być rzeczywiście rankingowana.
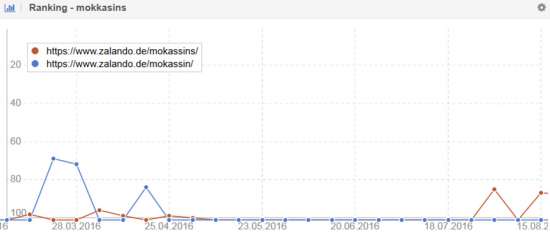
Najlepszy sposób na rozpoznanie takich problemów na podstawie Ranking -Rozwój pewności Słowa kluczowe : Jeśli wiele adresów URL do odpowiedniego słowa kluczowego regularnie zmienia się w rankingu, jest to wyraźny znak, że wyszukiwarka nie może zdecydować, która ze stron jest bardziej odpowiednia. W najgorszym przypadku może to prowadzić do tego, że żadna ze stron nie uzyska większej liczby rankingów.
4 źródła błędów Architektura informacji w sklepach internetowych
Każdy sklep ma inne przyczyny takich powielonych treści lub problemów z kanibalizacją. W wielu przypadkach jest to spowodowane jedną z następujących sytuacji:
- Podkategorie są tworzone dwukrotnie
- Strony produktów są podporządkowane kategoriom
- Tworzenie kategorii marki i kombinacji kategorii i marki
- Nowe strony nie mogą być zintegrowane z normalną architekturą informacji
Te cztery źródła błędów opisano poniżej.
1. Podwójne podkategorie
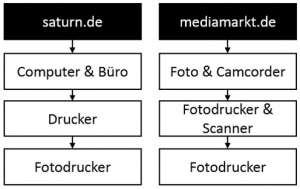
Często istnieje wiele podkategorii, które można przypisać do kilku głównych kategorii. Weźmy na przykład „drukarki fotograficzne” w sklepie z elektroniką: gdzie należy zorganizować tę kategorię - w „Komputer” lub w „Zdjęcie”? Sklepy internetowe rozwiązują to inaczej:
Saturn.de i mediamarkt.de łączą tę kategorię tylko raz:
- saturn.de o „Computer & Office”: http://www.saturn.de/de/category/_fotodrucker-437038.html
- mediamarkt.de w „Photo & Camcorder”: http://www.mediamarkt.de/de/category/_fotodrucker-464123.html
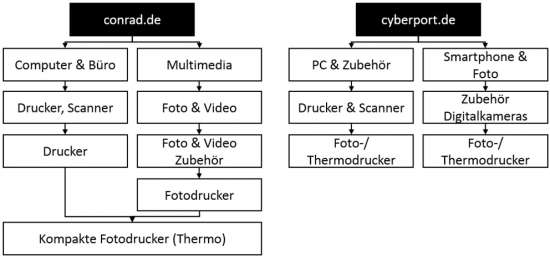
Jednak Conrad.de i cyberport.de zaaranżowały tę kategorię w kilku miejscach:
- Conrad.de mapuje kategorię zarówno na „Multimedia”, jak i „Komputer i biuro”, ale w obu przypadkach łączy to samo URL : https://www.conrad.de/de/kompakte-fotodrucker-thermo-o0405026.html.
- Cyberport.de mapuje kategorię za pomocą „PC & Accessories” oraz „Smartphone & Photo”, ale różne adresy URL są połączone: https://www.cyberport.de/pc-und-zubehoer/drucker-scanner/ zdjęcie - thermalprinter / list.html i https://www.cyberport.de/smartphone-and-foto/zubehoer-digitalkameras/foto--thermodrucker/liste.html
Teraz cyberport.de ma dwie równe podkategorie. W perspektywie krótkoterminowej całość można kontrolować za pomocą zarządzania indeksowaniem: meta roboty -Wprowadzenia adresu URL pod „Smartphone i zdjęcie” zostały ustawione na noindex . Czy jest na domena ale wiele takich duplikatów oznacza, że wiele stron jest niepotrzebnie indeksowanych.
Na dłuższą metę architektura strony musiałaby zostać zmieniona, tak aby istniał tylko jeden z dwóch adresów URL, ale oba są połączone odpowiednią kategorią, tak jak w przypadku conrad.de.
Aby uniknąć takiej późniejszej adaptacji, należy zauważyć, że podczas tworzenia strony
- Jest tak mało kategorii, jak to możliwe, które można przypisać wiele razy
- Żadne kategorie nie mogą być tworzone dwukrotnie
- Podkategorie można również łączyć z innymi głównymi kategoriami
Takie duplikowanie może również wystąpić, jeśli istnieją dodatkowe katalogi, w których wszystkie kategorie są tworzone ponownie, np. B. / sprzedaż, / nowe, / oferty, / sprzedawca itp. W tych przypadkach nawet wszystkie kategorie istnieją dwukrotnie. Dlatego od samego początku należy rozważyć, czy treść ta powinna być wyświetlana w autonomicznych adresach URL: o ile nie są one zoptymalizowane pod kątem własnych zestawów słów kluczowych, które mają kombinacje z „tanią”, „sprzedażą”, „ofertami”, „nowymi” itp. , powinny być pominięte, jak to możliwe, w tych katalogach. Zamiast tego adresy URL mogą być tworzone jako adresy URL parametrów indeksowania być jak najbardziej efektywnym.
Przykład : Planet Sports ma katalog / placówkę / gdzie wszystkie kategorie są ponownie mapowane:
- Kurtki w normalnej kategorii string: https://www.planet-sports.de/streetwear/jacken/winterjacken/
- Kurtki w / outlet / katalog: https://www.planet-sports.de/outlet/streetwear/jacken/winterjacken/
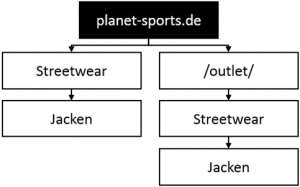
W takim przypadku indeksowanie zduplikowanych kategorii jest uniemożliwione przez ustawienie wszystkich stron w katalogu / outlet / na noindex .
2. Podwójne strony produktów
Podobnie jest w przypadku produktów tworzonych poniżej kategorii. Jeśli produkt może zostać przypisany do wielu kategorii, zostanie on podany dwa razy lub nawet częściej.
Przykład : notebooksbilliger.de ma taką strukturę, że adresy URL produktów znajdują się pod adresami URL kategorii. Teraz są produkty zarówno w głównych kategoriach, np. Jako „notatniki”, a także podkategorie, np. B. „Notebooki biznesowe”. Więc gdzie jest zorganizowany konkretny notatnik biznesowy? Ponieważ jest to istotne zarówno dla kategorii nadrzędnej, jak i podkategorii, sklep elektroniczny umieszcza go dwukrotnie:
- W sekcji „Notebooki”: https://www.notebooksbilliger.de/notebooks/hp+probook+470+g3+t6q49et
- Pod „Business Notebooks”: https://www.notebooksbilliger.de/notebooks/business+notebooks/hp+probook+470+g3+t6q49et
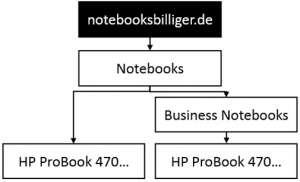
Chociaż może być całkiem pozytywnie tworzyć adresy URL produktów na stronach kategorii, szczególnie po to, aby podążać za pomysłem silosu. Powinno to jednak mieć miejsce tylko wtedy, gdy istnieje jasne rozwiązanie problemu, który właśnie wyjaśniono, tj .:
- Brak produktów, które można przypisać do wielu kategorii. Uwaga : należy upewnić się, że tak nie będzie w przyszłości.
- Każdy produkt może być przypisany tylko do jednej kategorii.
- Jeśli produkt jest odpowiedni dla kilku kategorii, można go powiązać z tych kategorii, ale nie zostanie wygenerowany żaden nowy adres URL.
Takie podejście jest jednak zbyt skomplikowane dla wielu sklepów internetowych, dlatego produkty rzadko są klasyfikowane poniżej kategorii. W tym przypadku zarówno użytkownik, jak i wyszukiwarka mogą być uważane za podrzędną rolę produktów za pomocą wewnętrznego łączenia. To może być jedno breadcrumb w których produkty nadal odnoszą się do kategorii macierzystych, nawet jeśli nie znajdują się w architekturze informacji w kategoriach. Ponownie jednak należy zdecydować się na ścieżkę kategorii.
3. Strony z podwójną marką
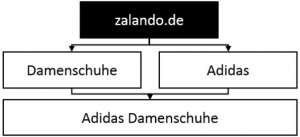
Wielu sprzedawców internetowych oferuje produkty wielu marek i ma je na własną rękę Miejsca tworzył także adresy URL dla różnych marek i kategorii marek lub kombinacji kategorii / marki. Na przykład Zalando ma stronę „Buty damskie Adidas”: https://www.zalando.de/damenschuhe/adidas/.
Ale skąd ta strona powinna być dostępna: ze strony marki „Adidas” lub ze strony kategorii „buty damskie”? Oba przypadki dotyczą Zalando. Jeśli klikniesz „Buty” na stronie marki „Adidas”, dojdziesz do powyższej strony. Możesz także uzyskać dostęp do tego adresu URL, wybierając markę „Adidas” na stronie kategorii „Obuwie damskie”. Ta implementacja jest optymalna: istnieje tylko jedna strona kategorii dla obuwia damskiego Adidas.
Często jednak sklepy internetowe uzyskują adresy URL z przewodnika nawigacyjnego, co skutkuje dwoma różnymi adresami URL dla tego samego tematu. W przypadku butów Adidas pojawiłby się adres URL do butów + Adidas i jeden do butów Adidas +. To na przykład. B. w Planet Sports sprawa:
- Kategoria „Buty” pod marką „Adidas”: https://www.planet-sports.de/marken/adidas/schuhe/
- Marka „Adidas” w kategorii „Buty”: https://www.planet-sports.de/schuhe/marke-adidas/
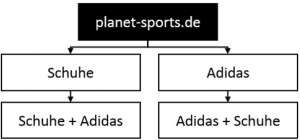
W takim przypadku byłyby dwie identyczne strony, obie zoptymalizowane dla tego samego zestawu słów kluczowych. W najgorszym przypadku żadna z dwóch stron nie będzie miała tutaj rangi. Aby temu zapobiec, architektura informacji powinna być od samego początku tak skonstruowana, aby istniała tylko jedna struktura URL dla kombinacji markowych. Te kombinacje powinny być dostępne zarówno na stronach marek, jak i kategoriach, jak to robi Zalando.
To, czy strony są zbudowane w nici marki, czy w nici kategorii, zależy od modelu biznesowego. Jeśli strony kategorii są najważniejsze dla sklepu, to kombinacje kategorii marki powinny być umieszczone poniżej. W niektórych przypadkach strony marek mogą być ważniejsze niż strony kategorii. W takim przypadku kombinacje należy umieścić pod stronami marek, aby je wzmocnić.
4. Nieistniejące strony
Oprócz treści transakcyjnych konwersje przynieś (zwłaszcza strony kategorii i produktów) powinny być na wszystkich witryna internetowa treść informacyjna jest zintegrowana. To może być w postaci a blogi lub magazyn, ale także bezpośrednio w treści transakcyjnej. Ważne jest, aby ten typ strony był już przemyślany podczas budowania strony, aby później łatwiej było go zintegrować. Czasami jednak nie jest to brane pod uwagę podczas tworzenia strony internetowej.
Ponadto często nie ma myśli o nowych stronach kategorii, które z czasem mogą okazać się niezbędne. Problem leży w technicznych możliwościach, które utrudniają, na przykład, wprowadzenie kolejnego poziomu kategorii lub obowiązków w firmie. Przykładem pierwszego przypadku byłby sklep internetowy, który ma trzy poziomy kategorii:
Teraz już istniejące Strony docelowe już zoptymalizowane i nowe potencjały słów kluczowych mają zostać wykorzystane. Jedną z możliwości byłoby stworzenie stron dla różnych typów dżinsów, np. Na przykład w przypadku jeansów typu skinny (w końcu 12 100 zapytań miesięcznie). Logiczne byłoby umieszczenie tej strony w dżinsach - ale musi być możliwe wstawienie innego poziomu kategorii.
Jednak w większości przypadków jest to drugi problem: obowiązki w firmie, tj. Kto może zdecydować, że potrzebny jest czwarty poziom kategorii lub trzeba utworzyć nową kategorię? Aby temu zapobiec, powinno być już uregulowane podczas tworzenia strony, że w pewnych okolicznościach utworzenie nowej kategorii nie stanowi problemu. W tym celu można zebrać odpowiednie kryteria z różnych działów, z. B. Znacząca objętość wyszukiwania dla słowa kluczowego.
streszczenie
Podczas opracowywania architektury strony należy odpowiedzieć na następujące pytania:
- Które strony lub typy stron są blisko spokrewnione i dlatego muszą być połączone za pomocą architektury informacji?
- Które strony lub typy stron nie mogą być przypisane jednoznacznie, a zatem nie powinny być powiązane w architekturze informacji?
- Czy planowana architektura informacji może tworzyć duplikaty zadań, których należy unikać?
- Które treści lub strony można utworzyć w przyszłości i gdzie są one ustawione?
- Gdzie idzie użytkownik, jeśli ustawia filtry w pewnych kategoriach i podwaja wynik?
Jeśli te pytania zostaną uwzględnione, architektura informacji na stronie powinna być stabilna i nie podatna na błędy.
O autorach
 Lydia jest przypadkowa SEO Konsultant w online marketing -Agentur Performics w Berlinie. Przed dołączeniem do strony agencji Search engine optimization Pracowała nad stroną korporacyjną w marketingu online, a zwłaszcza w SEO i Media społecznościowe odpowiedzialny.
Lydia jest przypadkowa SEO Konsultant w online marketing -Agentur Performics w Berlinie. Przed dołączeniem do strony agencji Search engine optimization Pracowała nad stroną korporacyjną w marketingu online, a zwłaszcza w SEO i Media społecznościowe odpowiedzialny.
 Matthäus Michalik jest starszym konsultantem w Performics, wiodącej na świecie agencji marketingu publicznego Publicis Media. Jako globalna agencja Performics doradza firmom w zakresie wyszukiwania, mediów społecznościowych, Marketing treści , Wyświetl reklamy i jest międzynarodowa strony internetowe i specjalizuje się w projektach. Matthäus zbudował międzynarodowy zespół pomocniczy w agencji, który zarządza firmami w 16 językach i ponad 20 krajach. Swoją wiedzą doradza projektom i korporacjom w kwestiach związanych ze strategiczną i techniczną optymalizacją wyszukiwarek (SEO), optymalizacją sklepów z aplikacjami (ASO) i optymalizacją rynku (MPO).
Matthäus Michalik jest starszym konsultantem w Performics, wiodącej na świecie agencji marketingu publicznego Publicis Media. Jako globalna agencja Performics doradza firmom w zakresie wyszukiwania, mediów społecznościowych, Marketing treści , Wyświetl reklamy i jest międzynarodowa strony internetowe i specjalizuje się w projektach. Matthäus zbudował międzynarodowy zespół pomocniczy w agencji, który zarządza firmami w 16 językach i ponad 20 krajach. Swoją wiedzą doradza projektom i korporacjom w kwestiach związanych ze strategiczną i techniczną optymalizacją wyszukiwarek (SEO), optymalizacją sklepów z aplikacjami (ASO) i optymalizacją rynku (MPO).
Które typy stron odgrywają rolę w strukturze?
Weźmy na przykład „drukarki fotograficzne” w sklepie z elektroniką: gdzie należy zorganizować tę kategorię - w „Komputer” lub w „Zdjęcie”?
Więc gdzie jest zorganizowany konkretny notatnik biznesowy?
Ale skąd ta strona powinna być dostępna: ze strony marki „Adidas” lub ze strony kategorii „buty damskie”?
Kto może zdecydować, że potrzebny jest czwarty poziom kategorii lub trzeba utworzyć nową kategorię?
Które strony lub typy stron nie mogą być przypisane jednoznacznie, a zatem nie powinny być powiązane w architekturze informacji?
Czy planowana architektura informacji może tworzyć duplikaty zadań, których należy unikać?
Które treści lub strony można utworzyć w przyszłości i gdzie są one ustawione?
Gdzie idzie użytkownik, jeśli ustawia filtry w pewnych kategoriach i podwaja wynik?


