
- Одностраничное приложение SEO
- Простое приложение React
- Используя Fetch как Google
- Эксперименты
- Резюме
При разработке веб-сайта вам может быть интересно понять, насколько хорошо поисковые системы могут сканировать и понимать его. Google предлагает инструмент под названием Просмотреть как Google это может помочь ответить на этот вопрос.
В этом посте я объясню, как использовать Fetch в качестве Google для тестирования вашего сайта. Может использоваться для любого сайта; Тем не менее, я собираюсь сосредоточиться на тестировании SEO видимости реагировать приложения, так как в настоящее время я работаю над общедоступным веб-приложением React.
Одностраничное приложение SEO
Переход к одностраничным приложениям (например, React, угловатый , тлеющие угли и т. д.) изменился способ доставки контента пользователям. Из-за этого поисковым системам приходилось настраивать способ сканирования и индексирования веб-контента.
Так что же это означает для одностраничного SEO приложения? Там были несколько отличный сообщений эта попытка расследовать это. Общий вывод заключается в том, что Google и другие поисковые системы могут сканировать и индексировать эти приложения с довольно хорошей компетенцией. Однако могут быть оговорки, поэтому очень важно иметь возможность протестировать свой сайт. Это где Fetch, как Google входит.
По словам самого Google:
Инструмент «Получить из Google» позволяет вам проверить, как Google сканирует или отображает URL на вашем сайте. Вы можете использовать Fetch as Google, чтобы узнать, может ли робот Google получить доступ к странице на вашем сайте, как он отображает страницу и заблокированы ли какие-либо ресурсы страницы (например, изображения или скрипты) для робота Googlebot. Этот инструмент имитирует выполнение сканирования и рендеринга, как в обычном процессе сканирования и рендеринга Google, и полезен для устранения проблем сканирования на вашем сайте.
Простое приложение React
Чтобы поэкспериментировать с Fetch в качестве Google, нам сначала понадобится веб-сайт (приложение React для нас) и способ его развертывания по общедоступному URL-адресу.
В этом посте я собираюсь использовать простое приложение React «Здравствуй, мир!», Которое я разверну в Heroku для тестирования. Несмотря на то, что приложение простое, концепции хорошо обобщаются для более сложных приложений React (по моему опыту).
Предположим, что наше простое приложение React выглядит следующим образом:
Приложение класса расширяет React.Component {render () {return (<div> <h1> Hello, World! </ h1> </ div>)}}
Используя Fetch как Google
Вы можете найти Fetch как инструмент Google под Google Search Console , (Вам понадобится учетная запись Gmail для доступа.)
Когда вы попадете в консоль поиска, она будет выглядеть примерно так:
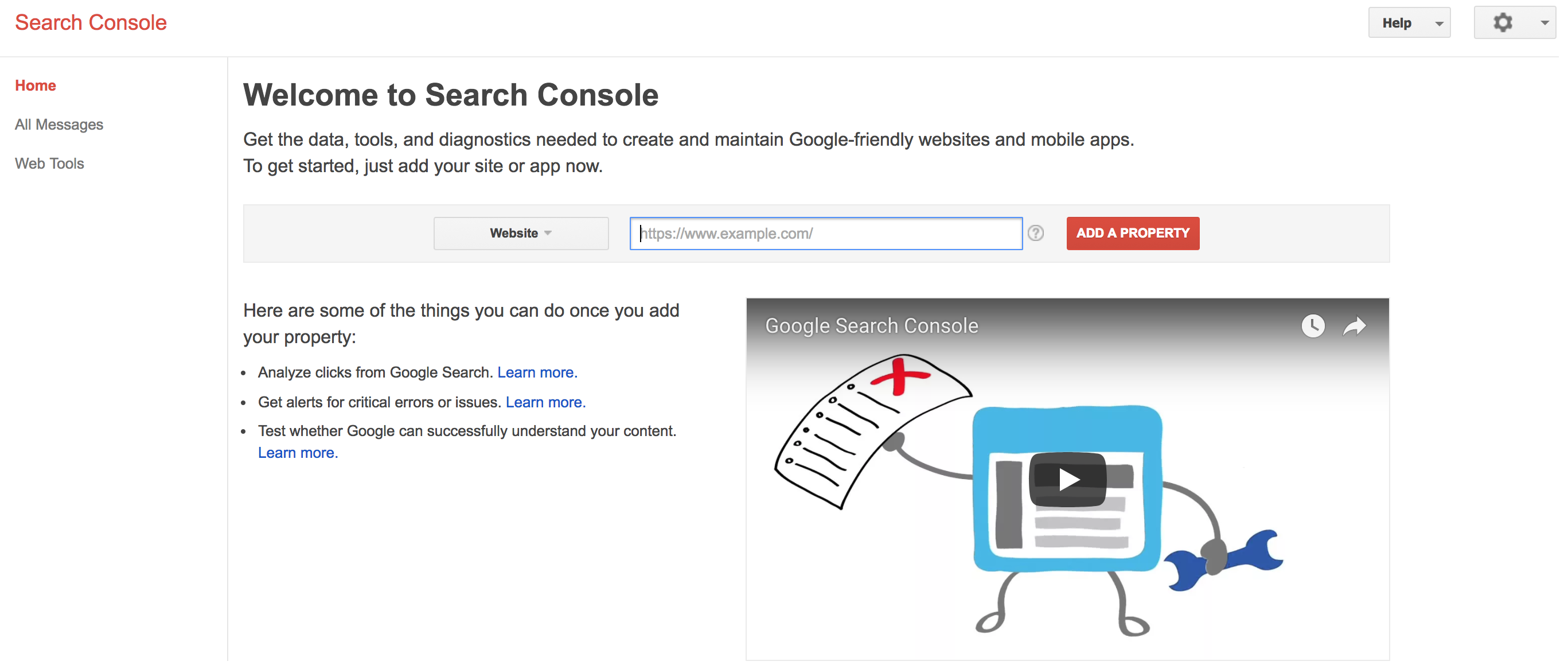
Поисковая консоль сначала запрашивает веб-сайт. Мое приложение Heroku размещено по адресу https://react-seo-demo.herokuapp.com/. Введите URL своего веб-сайта, а затем нажмите Добавить свойство.
Затем консоль поиска попросит вас подтвердить, что вы являетесь владельцем URL, который вы хотите проверить.
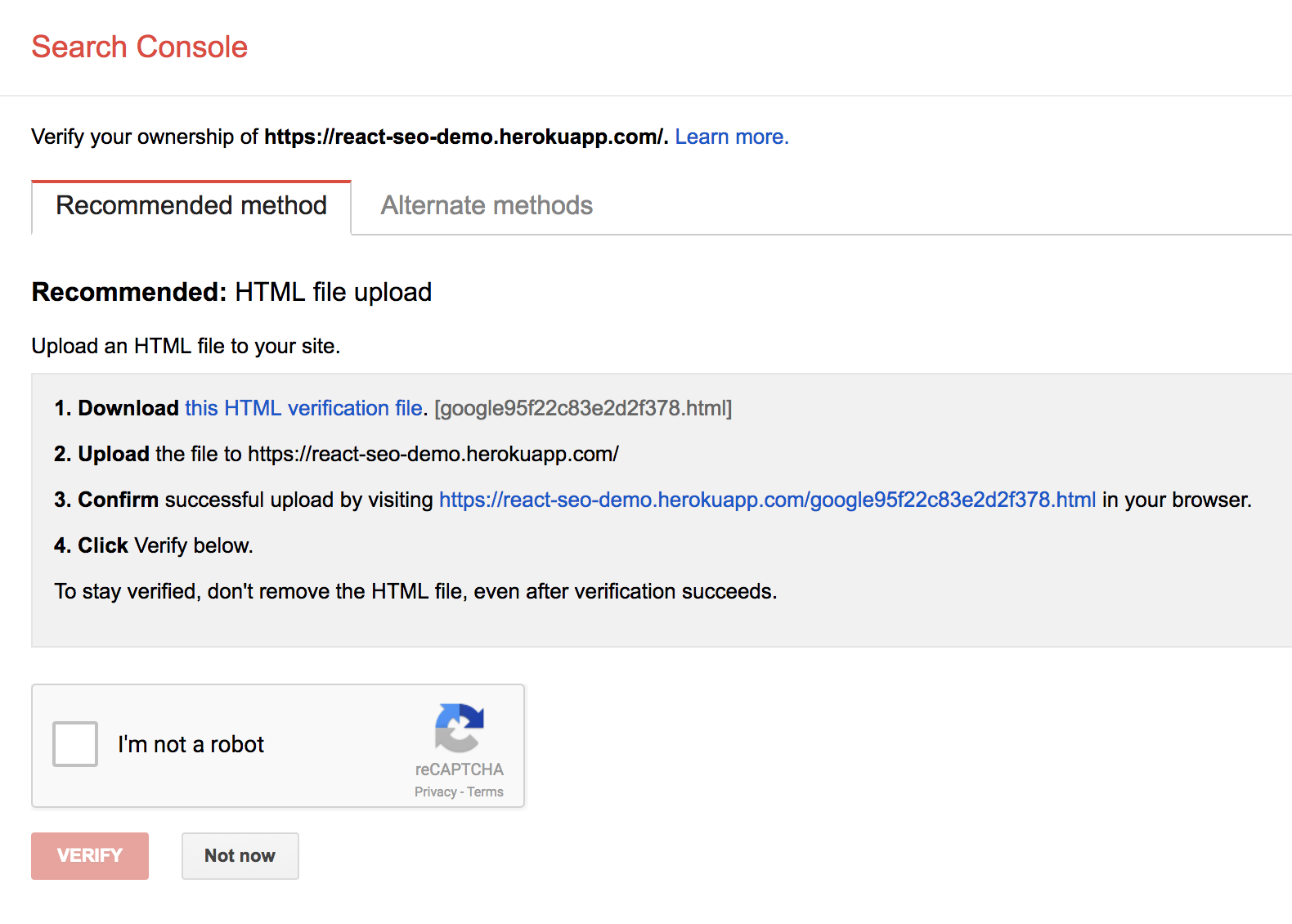
Способ проверки зависит от того, как размещен ваш сайт. Для моего сайта мне нужно было скопировать проверочный HTML-файл, предоставленный Google, в корневой каталог моего сайта, а затем открыть его в браузере.
После проверки вашего URL, вы должны увидеть следующее меню:
Под опцией Crawl вы должны увидеть Fetch как Google:
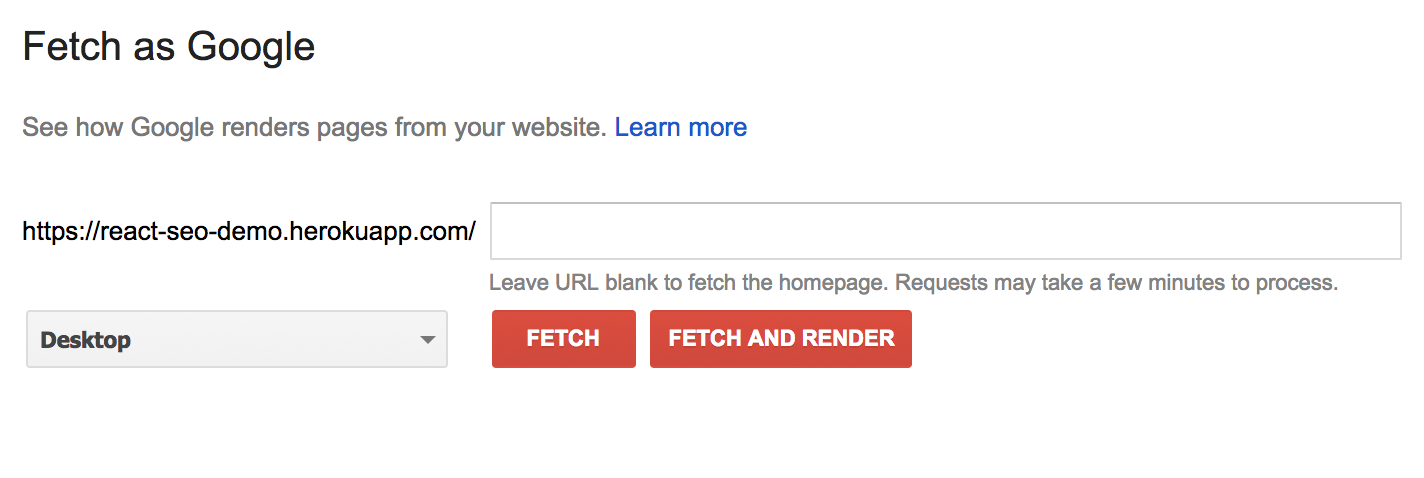
Получить как Google позволяет вам тестировать конкретные ссылки, указав их в текстовом поле. Например, если у нас есть страница / users и мы хотим проверить это, мы можем ввести / users в текстовое поле. Оставьте это поле пустым, чтобы протестировать индексную страницу сайта.
Вы можете проверить, используя два разных режима: Fetch, и Fetch and Render. Как описано в Google, Fetch:
Получает указанный URL на вашем сайте и отображает ответ HTTP. Не запрашивает и не запускает никаких связанных ресурсов (таких как изображения или сценарии) на странице.
И наоборот, выборка и рендеринг:
Выбирает указанный URL-адрес на вашем сайте, отображает HTTP-ответ, а также отображает страницу в соответствии с указанной платформой (настольный компьютер или смартфон). Эта операция запрашивает и запускает все ресурсы на странице (например, изображения и сценарии). Используйте это, чтобы обнаружить визуальные различия между тем, как робот Google видит вашу страницу, и тем, как пользователь видит вашу страницу.
Запуск Fetch на нашем тестовом сайте React дает:
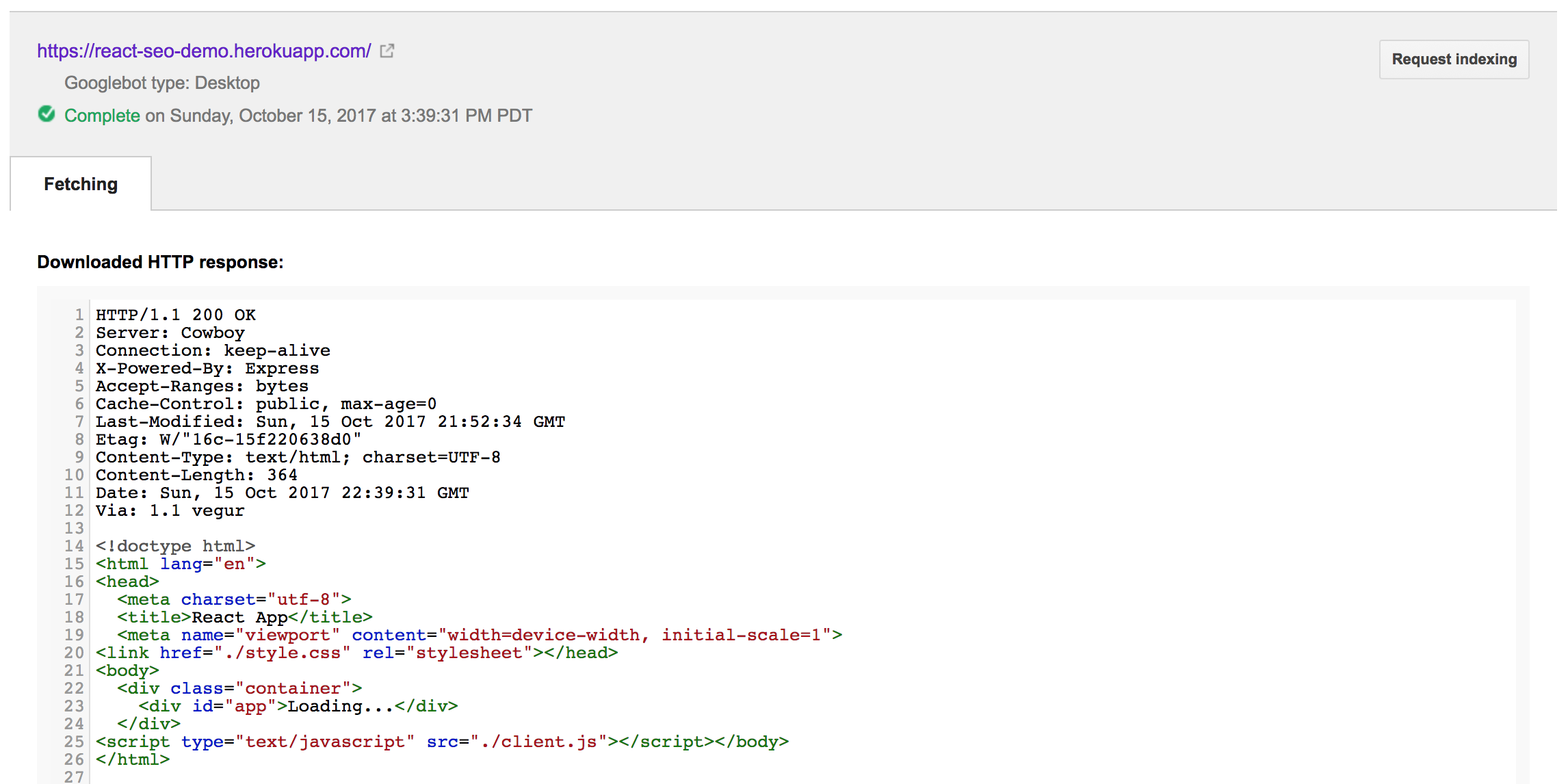
Это отражает страницу index.html, в которой находится наше приложение React. Обратите внимание, что это отражает HTML, когда страница загружается, до того, как наше приложение React будет отображено внутри div приложения.
Запуск Fetch and Render дает:
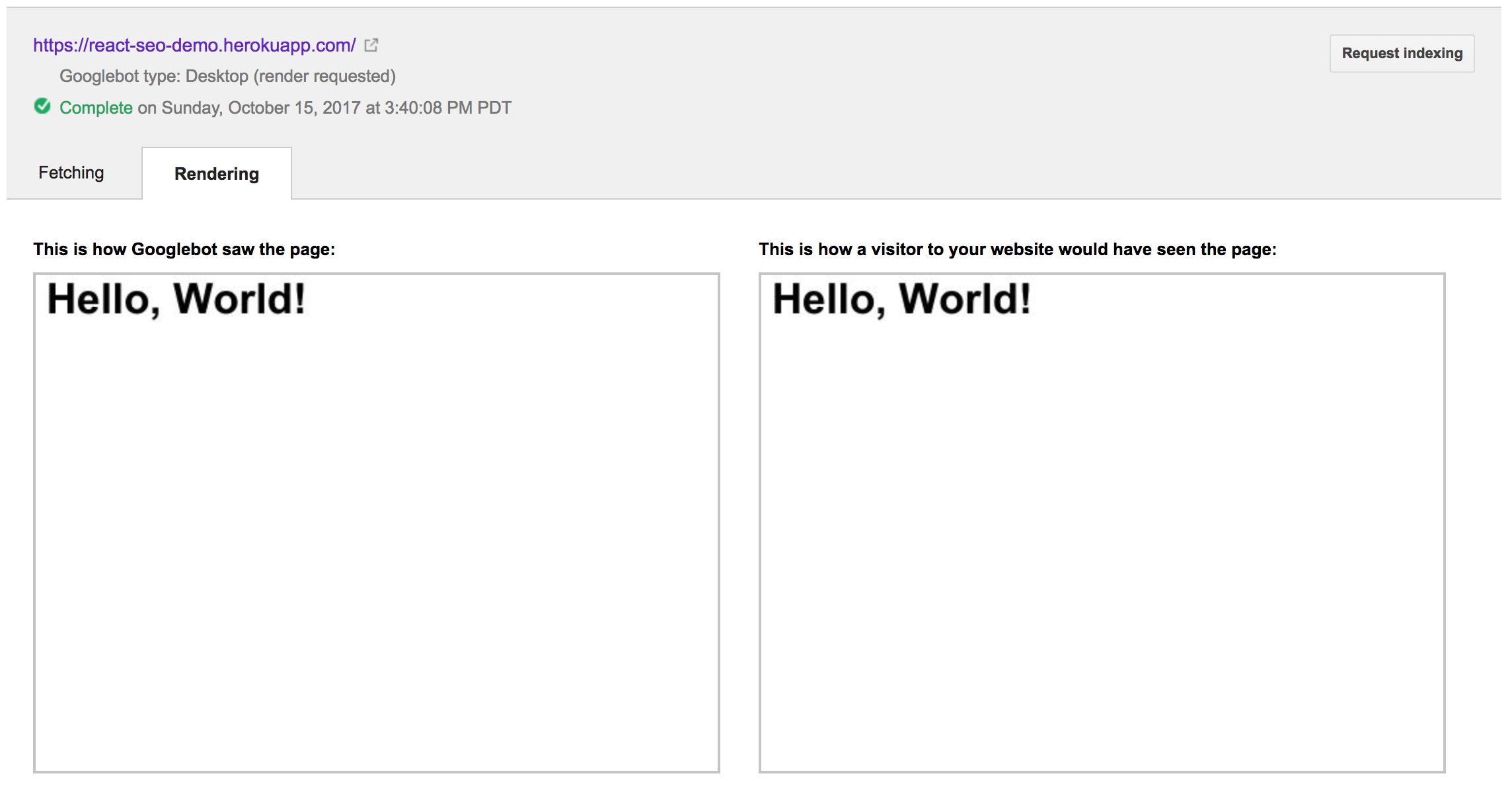
Это обеспечивает сравнение сайта, который робот Google может видеть с тем, что пользователь сайта будет видеть в своем браузере. Для нашего примера они точно такие же, что является хорошей новостью для нас!
В Интернете есть несколько историй о людях, которые запускали Fetch as Google в своих приложениях React и наблюдали пустой или другой вывод «Это то, как робот Googlebot видел страницу». Это может указывать на то, что ваше приложение React разработано таким образом, что не позволяет Google и, возможно, другим поисковым системам правильно читать и сканировать.
Это может произойти по разным причинам, одной из которых может быть слишком медленная загрузка контента. Если ваш контент загружается медленно, есть вероятность, что сканер не будет ждать его достаточно долго. Это не было проблемой в нашем примере выше. Я также запустил Fetch as Google на достаточно большом веб-сайте React, который выполняет несколько асинхронных вызовов для получения исходных данных, и он мог видеть все просто отлично.
Так какой предел? Я решил провести несколько наивных экспериментов.
Эксперименты
Примечание : я не уверен, как Fetch как Google работает под капотом. Есть некоторые посты это намек на то, что он может сделать ваш сайт с помощью PhantomJS ,
Реагирующие приложения обычно полагаются на асинхронные вызовы для извлечения своих начальных данных. Чтобы отразить это, давайте обновим наш пример приложения React, чтобы получить некоторые репозитории GitHub и отобразить список их имен.
Приложение класса расширяет React.Component {constructor () {super (); this.state = {repoNames: []}; } componentDidMount () {let self = this; fetch ("https://api.github.com/repositories", {method: 'get'}) .then ((response) => {return response.json ();}) .then ((repos) => {self.setState ({repoNames: repos.map ((r) => {return r.name;})});}); } render () {return (<ol> {this.state.repoNames.map ((r, i) => {return <li key = {i}> {r} </ li>})} </ ol> )}}
Запуск вышеупомянутого через Fetch, поскольку Google производит следующий вывод:
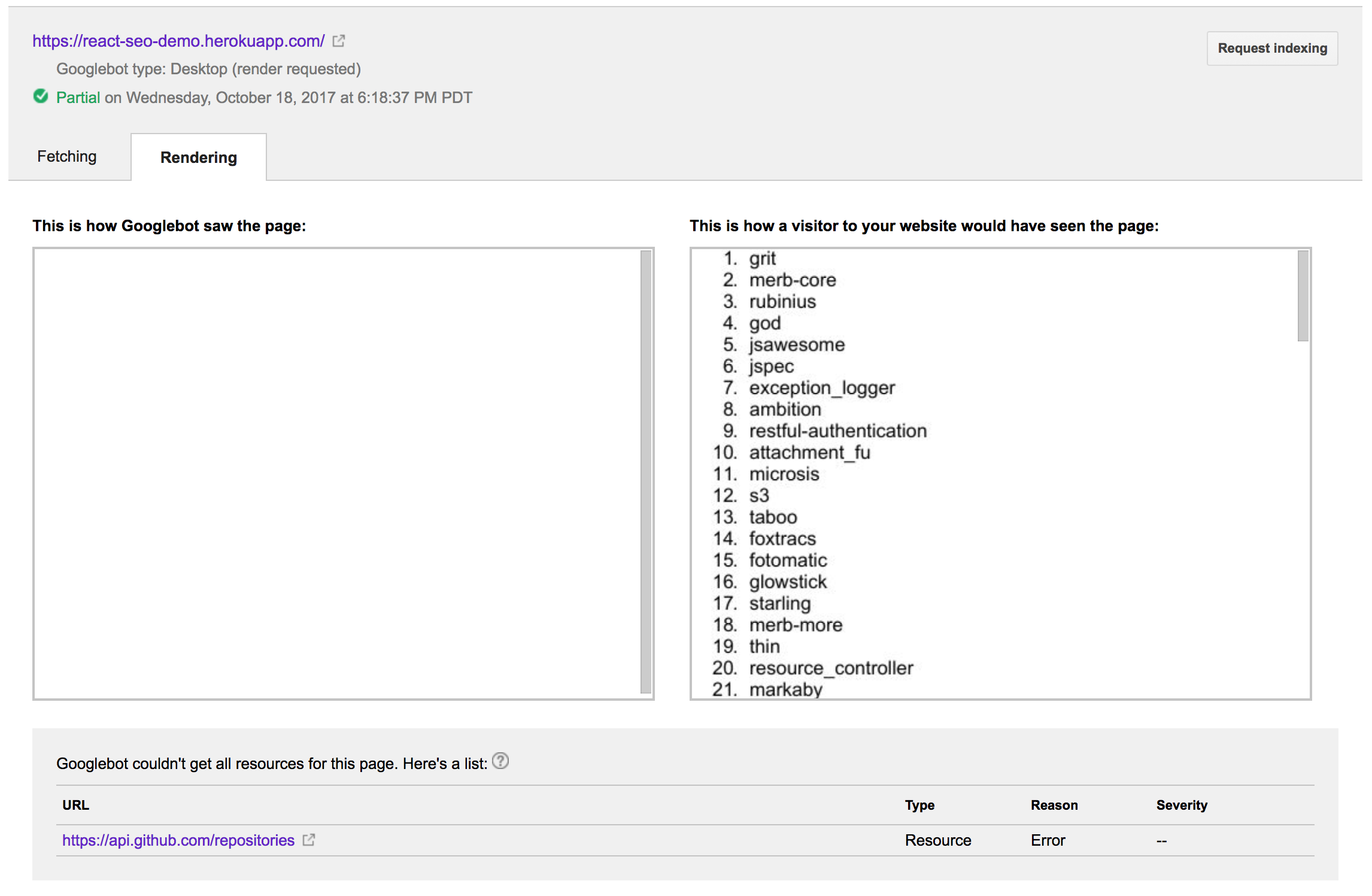
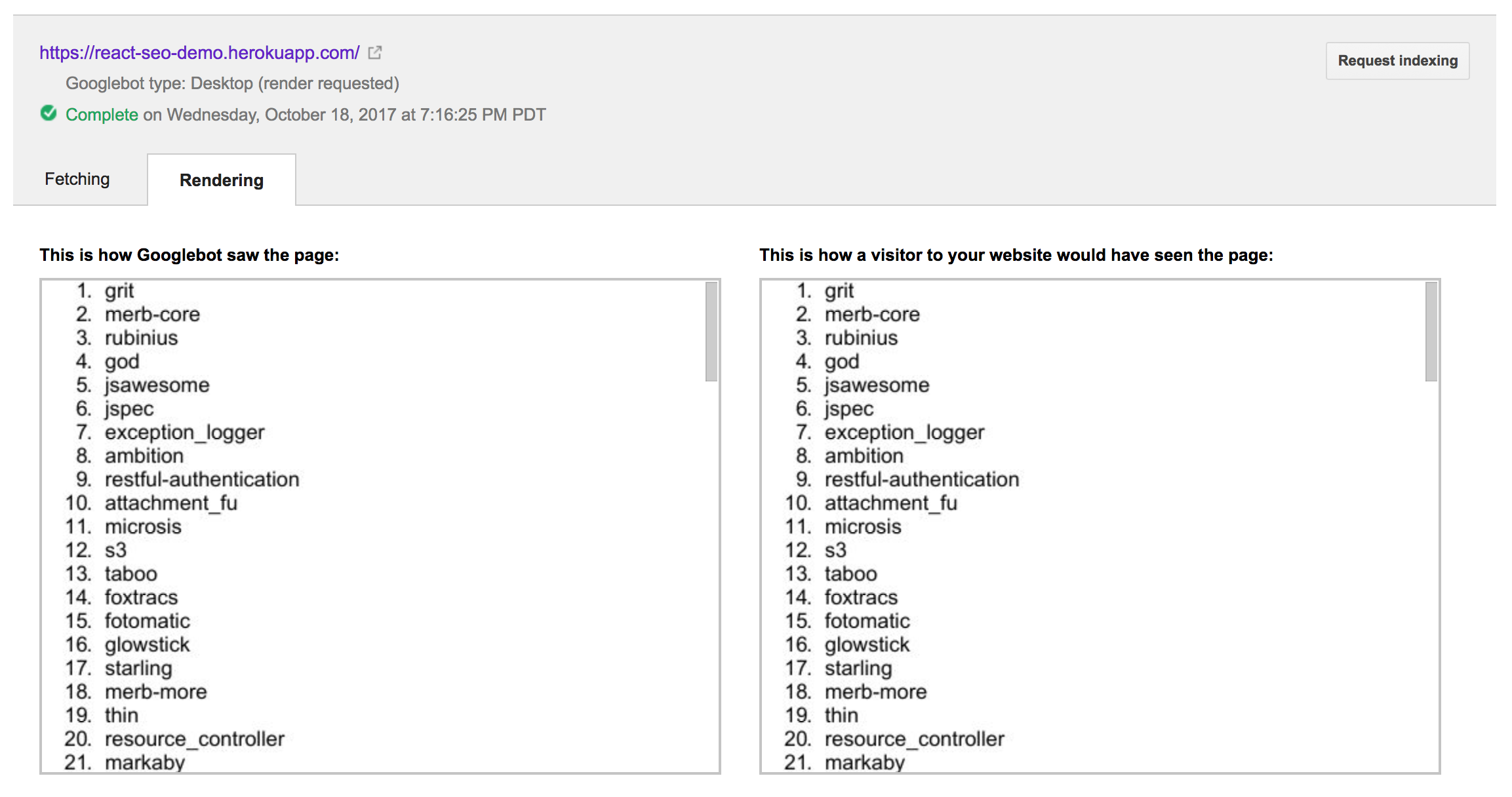
о нет! Не удалось увидеть данные из асинхронного вызова GitHub. Я буду честен; это немного смутило меня. Сначала я подумал, что это может быть какое-то странное ограничение перекрестного происхождения. Однако оказывается, что робот Googlebot может обрабатывать запросы из разных источников просто отлично. После нескольких копаний, множества проб и ошибок и, но удачи, я обнаружил, что мне нужно включить полифилл ES6 Promise. Очевидно, что браузер, в котором работает робот Google, не содержит реализацию ES6 Promise. После внесения в ES6-обещание , Выборка как вывод Google выглядела так.
Давайте выберем в Fetch как Google немного больше. Предположим, что ваше приложение выполняет медленный вызов или выполняет некоторую асинхронную обработку, используя такие вещи, как setTimeout или setInterval. Как долго Fetch будет ждать, пока Google будет ожидать таких типов асинхронных запросов, и когда она получит снимок вашего веб-сайта?
Давайте изменим наше приложение «Hello, World!» Сверху, чтобы подождать пять секунд, прежде чем отобразить текст «Hello, World!»:
Приложение класса расширяет React.Component {constructor () {super (); this.state = {message: ""}; } componentDidMount () {setTimeout (() => {this.setState ({message: "Hello World !, через 5 секунд"})}, 5000); } render () {return (<div> <h1> {this.state.message} </ h1> </ div>)}}
Запуск Fetch от Google с приведенным выше кодом дает следующее:
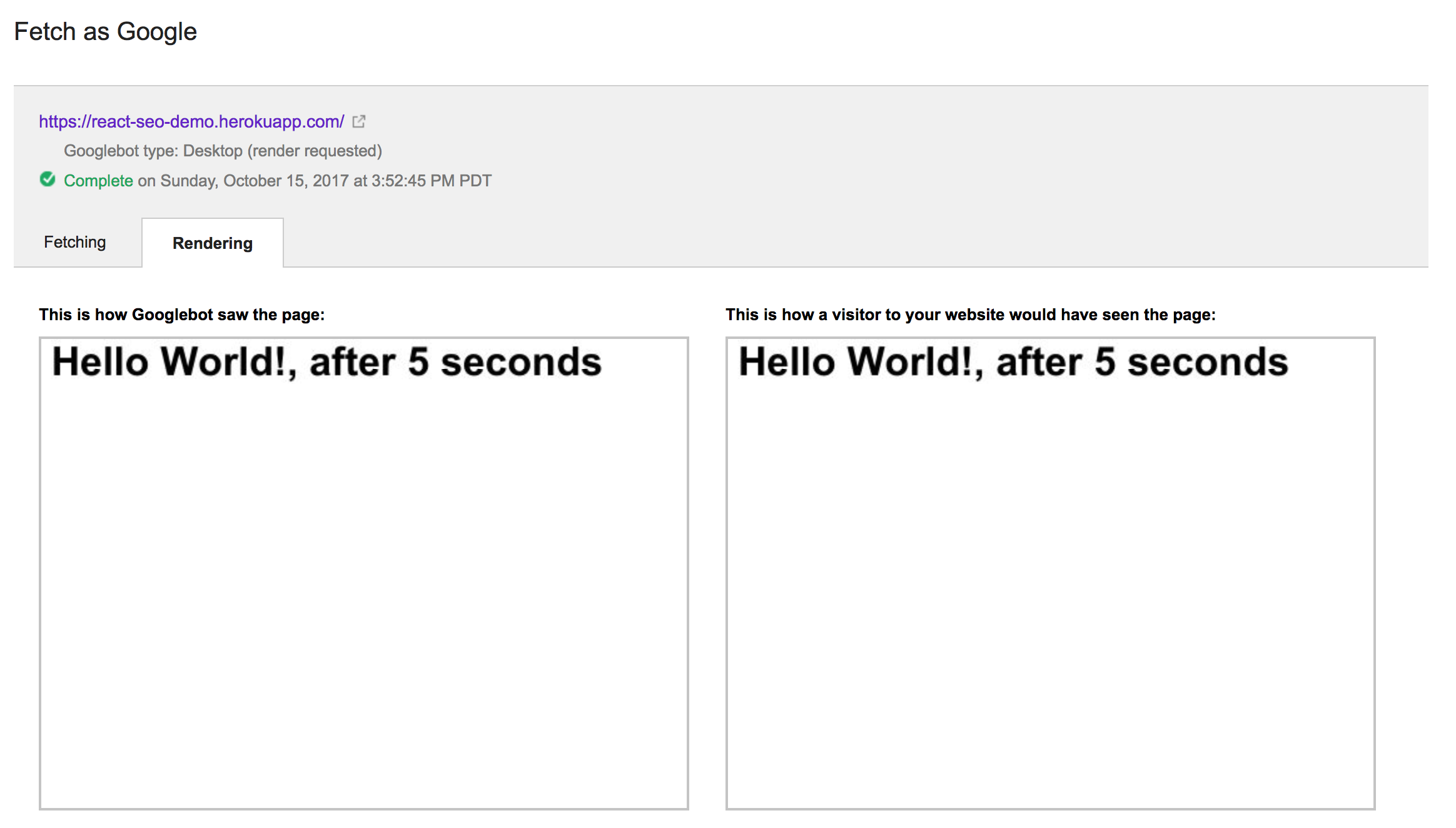
Интересно, что он все еще был в состоянии видеть выходные данные компонента. Кроме того, операция Fetch as Google заняла значительно меньше пяти секунд настенных часов, что заставляет меня думать, что среда браузера, в которой она работает, должна быть ускоренной пересылки из-за задержек или чего-то еще. Интересно, что если мы увеличим пять секунд до 15, мы увидим этот результат:
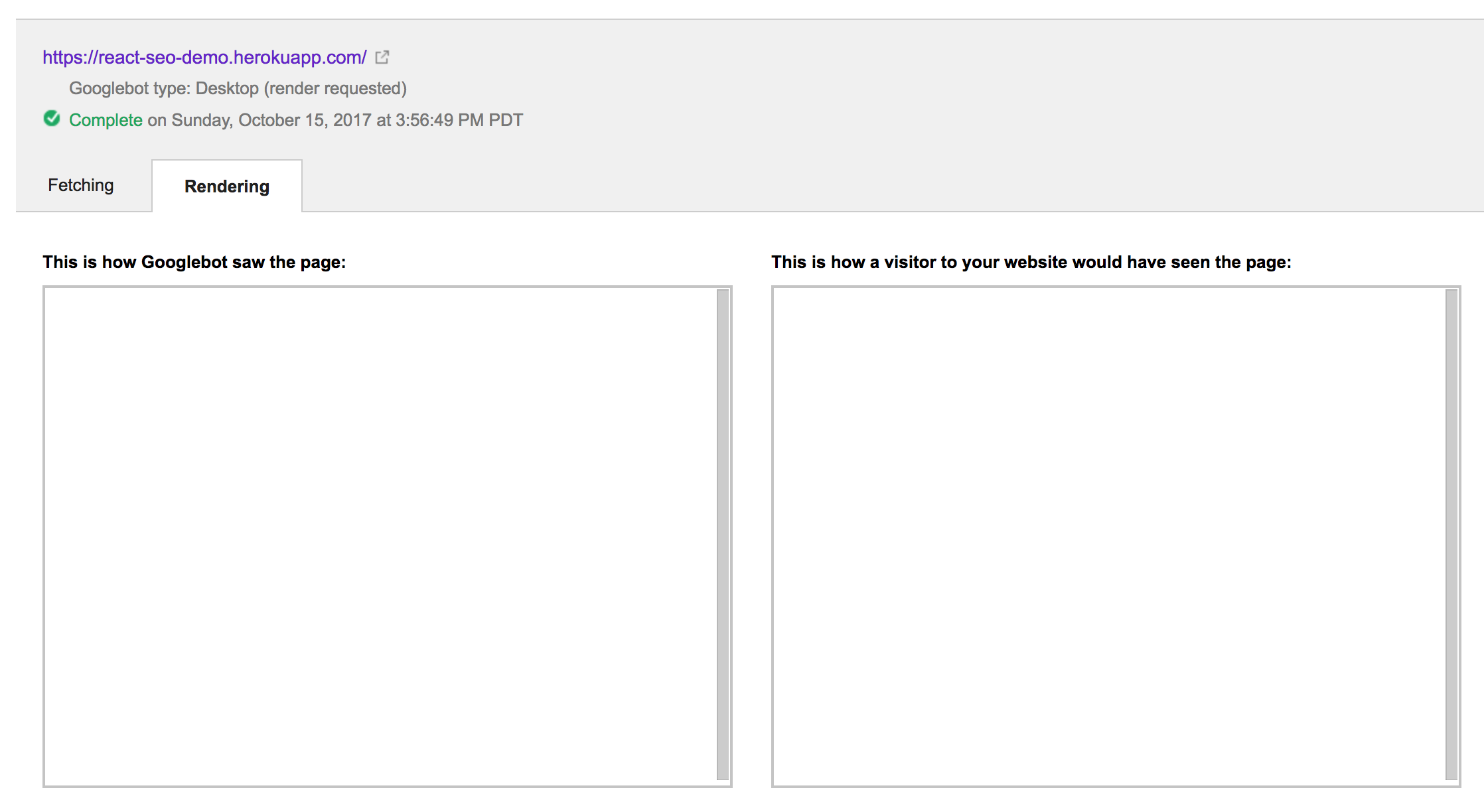
Я понятия не имею, как Google относится к setTimeout. Тем не менее, вышеприведенный тест указывает на то, что вещи, которые загружаются слишком долго, будут игнорироваться (не слишком удивительно).
Теперь давайте изменим наш компонент так, чтобы он вызывал setInterval каждую секунду, и обновим счетчик, который мы печатаем, на экран:
Приложение класса расширяет React.Component {constructor () {super (); this.state = {message: "", count: 0}; this.update = this.update.bind (this); } update () {let count = this.state.count; this.setState ({count: this.state.count + 1}); } componentDidMount () {setInterval (this.update, 1000); } render () {return (<div> <h1> {`Количество равно $ {this.state.count}`} </ h1> </ div>)}}
Это дает следующий вывод:
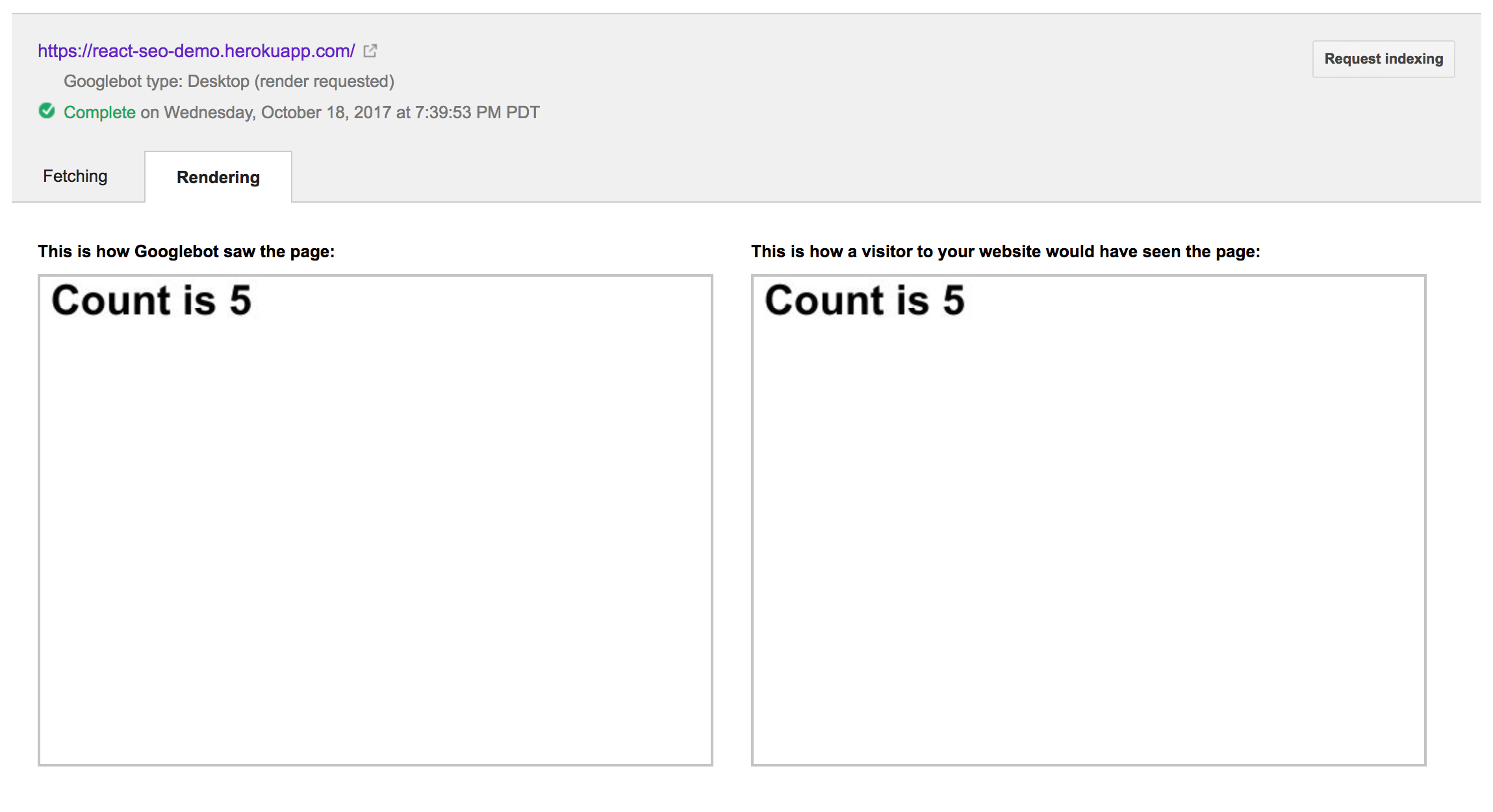
Таким образом, он захватил рендеринг страницы после ожидания в течение пяти секунд. Это соответствует приведенному выше поведению setTimeout. Я не уверен точно, сколько мы можем вывести из этих экспериментов; однако, они, похоже, подтверждают, что робот Google будет ждать некоторое время, прежде чем сохранить визуализацию вашего сайта.
Резюме
По моему опыту, Google может довольно эффективно сканировать сайты React, даже если они действительно загружают данные заранее. Однако, вероятно, хорошей идеей будет оптимизировать ваше приложение React, чтобы загружать наиболее важные данные (которые вы хотели бы сканировать) как можно быстрее при загрузке приложения. Это может означать упорядочение вызовов API определенным образом, предпочтение сначала загружать частичные данные или даже рендеринг начальной страницы на сервере, чтобы она сразу загружалась в браузере клиента.
Помимо времени загрузки, есть несколько других вещей, которые могут вызвать проблемы с SEO для вашего приложения React. Мы видели, что недостающие полифилы могут быть проблематичными. Я также видел, что использование функций со стрелками было проблематичным, поэтому, возможно, стоит ориентироваться на более старую версию ECMAScript.
Похожие
КАК ОПТИМИЗАЦИЯ SEO SEO?Итак, у нас есть четыре методологии, с помощью которых мы можем трансформировать слой нашего мира: файл конфигурации, луч внимания, проектор и бумеранг. Давайте посмотрим -R§S, RẑS, R ° RêRẑRμ SEO? -RćRїС, РЁРЧЕРС, РЕСУРСЫ, РЕСУРСЫ <РЕСУРСЫ, РЕСУРСЫ! Прибалтика, Москва, Россия,...
-R§S, RẑS, R ° RêRẑRμ SEO? -RćRїС, РЁРЧЕРС, РЕСУРСЫ, РЕСУРСЫ <РЕСУРСЫ, РЕСУРСЫ! Прибалтика, Москва, Россия, Россия, Россия, Россия Чёрный, Чёрный, Чёрный ... Прибалтика, Приморский край, Рио-де-Жанейро, Рибор, Рисбюринг, Рюсские острова , Ѓ Ѓ <ј <<<SEO SEO Консалтинг
SEO Консалтинг Получите всю информацию о видимости вашего бизнеса в результатах поиска Google с помощью нашей службы SEO Consulting . Наличие SEO-анализа на странице в вашей общей стратегии SEO имеет важное значение для улучшения позиций в обычных результатах поиска. SEO Консалтинг Seo Asesor - это процесс анализа различных специфических аспектов вашей веб-страницы, таких как текст и содержание изображений, SEO услуги
... seo/"> SEO услуги является расширением поисковой оптимизации или может быть интерпретировано путем оптимизации сайта / сети в глазах поисковых систем, таких как Google, Yahoo, Bing и многих других. Поскольку технологии становятся все более изощренными, сегодня многие предприятия расширяют свой бизнес через мир Интернета, потому что благодаря использованию интернет-технологий компании в реальном мире, ограниченные этим регионом, станут легко доступны во всех регионах Индонезии SEO специалисты
Bierzo SEO - это агентство по SEO и цифровому маркетингу, где мы хотим помочь вам добиться успеха в цифровом мире. Мы едины компания позиционирования в Интернете и в настоящее время у нас более 10 000 ключевых слов, размещенных в ТОП 10 Google. Аудит вашего сайта или вашего интернет-магазина Мы можем провести аудит вашего веб-сайта или магазина, чтобы вы знали, что не работает, и как Как страницы Google+ влияют на SEO
Google Plus растет с высокой скоростью. Со времени его внедрения в июне, первоначально только по приглашению, он собрал 50 миллионов пользователей; это 16-й из пользователей Facebook. 7 ноября Google Plus начал разрешать компаниям размещать профили (то Полиция SEO
... google-yahoo-live"> еще один сайт относительно недавно. Почему сайт вышел? Потому что они занимали место в SEO компании, и Рэнд не считал, что их обратные ссылки должны учитываться (и Рэнд хотел найти другое оправдание для продвижения своего нового инструмента LinkScape). В своем посте Рэнд ... утверждал, что рейтинг сайта № 1 для SEO компании был затруднительным для Google и других поисковых систем написал «Использование манипулятивных SEO аудит
Сайт Abondance предлагает SEO-аудит вашего сайта. Аудит, проведенный Оливье Андрие , признанным экспертом в мире французской референции, после отправки вам отправляется по почте в виде PDF-документа объемом около шестидесяти страниц, в котором перечисляется, что необходимо сделать на своем сайте, чтобы он лучше учитывался поисковыми системами, такими как Google, Bing или Yahoo! : Индексация Блог SEO - Статьи SEO - Новости SEO
... seo-stati-seo-novosti-seo-1.jpg" alt="Вице-президент Google по маркетингу для Северной и Южной Америки Лиза Джевелбер объясняет, как все больше и больше людей используют поиск для оптимизации своего реального опыта"> Вице-президент Google по маркетингу для Северной и Южной Америки Лиза Джевелбер объясняет, как все больше и больше людей используют поиск для оптимизации своего реального опыта. Вы ресторан одержимы? Вы знаете кого-то, кто есть? Если вы понимаете, о чем я. У вас Понимание SEO | Преимущества SEO | Виды SEO
Что такое SEO ? может быть, для начинающих блоггеры все еще должны быть в облаке с SEO, и какая польза от этого для нашего блога или веб-сайта. Понимание SEO - это сокращение от Поисковой оптимизации, »Hyein Seo
Джонатан Фэйерс - профессор модного мышления в Винчестерской школе искусств, Саутгемптонский университет. Великобритания Изначально изучая дизайн одежды в Central St. Martins, Джонатан работал театральным дизайнером и консультантом по розничной торговле в музее Виктории и Альберта, а также демонстрировал свои видео-работы
Комментарии
Как Google будет определять авторитетный и релевантный контент в 2020 году?Как Google будет определять авторитетный и релевантный контент в 2020 году? Какие показатели поведения пользователей может измерять Google в 2020 году? Как могут результаты органического поиска отображаться в 2020 году и как они будут интегрироваться с платным поиском? Как ИИ изменит SEO? Как вы думаете, отрицательный SEO может развиваться? Будем ли мы лучше в отслеживании между устройствами и мультитач атрибуции? Программное Влияют ли такие вещи, как количество лайков в Facebook, ретвиты в Твиттере и Google + 1, на то, как вы попали в рейтинг в Поиске Google?
Влияют ли такие вещи, как количество лайков в Facebook, ретвиты в Твиттере и Google + 1, на то, как вы попали в рейтинг в Поиске Google? Гуру SEO SponsoredLinx Tutai Marongere рассмотрит некоторые вещи, которые действительно повлияют на результаты вашего поиска. Что ж, простой и короткий ответ на этот вопрос - «Нет». Социальные сигналы не учитываются алгоритмом поиска Google. Сканеры Google ограничивают количество посещений сайтов и обрабатывают сайты социальных сетей, как и любой другой Как Google Crawl Budget подходит для SEO и как сайты сканируются, индексируются и ранжируются?
Как Google Crawl Budget подходит для SEO и как сайты сканируются, индексируются и ранжируются? Googlebot - это система, которая сканирует страницы веб-сайта (URL). Процесс в основном идет так: Google «обнаруживает» URL различными способами ( XML Sitemaps , внутренние ссылки , Как фильм влияет на идентичность, как это означает, как строит прошлое?
Как фильм влияет на идентичность, как это означает, как строит прошлое? Что случилось с фильмом в Венгрии? »,« ShortLead »:« Почему моя общественная мифология, а основной носитель мифологии, кино? Как работает фильм? e632-4abc-b367-3d9b3bb5573b "" индекс "0", пункт "" 026a2f3c-d95a-4b0d d03086d22bf2-9011 "" ключевые слова "нулевой" ссылка "" / культура / 20190524_Fabricius_Gabor_Film_irja_a_multat_igy_a_jelent_is "" метка времени Как часто бизнес должен оценивать SEO и как это лучше всего сделать?
Как часто бизнес должен оценивать SEO и как это лучше всего сделать? Компании всегда должны оценивать SEO, как и любой другой крупный маркетинговый канал. Это не означает, что это является ежедневной задачей для некоторых предприятий, но, безусловно, это должно быть ежемесячное рассмотрение с хорошими данными, чтобы помочь вам принимать обоснованные решения. Как, на ваш взгляд, «выигрывать» в SEO? Минимальный / расчетный риск без Как определить будущее использование в контексте новых алгоритмов Google, таких как Search Quality Rater?
Как определить будущее использование в контексте новых алгоритмов Google, таких как Search Quality Rater? Какие шаги для создания и управления PBN? 12:15 - 13:00. Оптимизация клиентского процесса в электронной торговле для повышения конверсии. Брахим Бен Хелал, директор по стратегическому развитию Trustpilot и Смайл Маакик, соучредитель платформы E-Works Но как работает Enterprise SEO и как это влияет на ваш бизнес?
Но как работает Enterprise SEO и как это влияет на ваш бизнес? Что такое SEO для предприятий? Прежде чем мы перейдем к его основным функциям, давайте сначала разберемся, что такое Enterprise SEO. В принципе, Предприятие SEO то же SEO - Как Google должен оценивать ваш сайт, если все ссылки называются «здесь»?
SEO - Как Google должен оценивать ваш сайт, если все ссылки называются «здесь»? Доступность - позволяет слабовидящим потребителям использовать программы чтения с экрана для просмотра 4. Добавленная стоимость на каждом этапе Мы часто проводим часы на наших любимых сайтах. Почему? Для каждой статьи, на которую мы нажимаем, есть, по крайней мере, так много интересных, на которые можно нажать. Вниз, внизу, во всплывающих окнах, сбоку - куда бы мы ни посмотрели. Итак, как вы разрабатываете стратегию, не имея представления о том, как Google может использовать ее в будущем?
Итак, как вы разрабатываете стратегию, не имея представления о том, как Google может использовать ее в будущем? Правило большого пальца, которое всегда предоставляла поисковая система, - это создавать ссылки естественным образом. Но мы все очень хорошо знаем, что идти по этому пути чрезвычайно трудно; особенно когда конкуренция идет очень хорошо с гораздо более сомнительной тактикой. Это не ошибка вашей SEO команды Большинство стартапов справляются со своей стратегией Если вы хотите больше информации о SEO оптимизации, ознакомьтесь с нашей статьей "Как добиться видимости с SEO?
Итак, как вы разрабатываете стратегию, не имея представления о том, как Google может использовать ее в будущем? Правило большого пальца, которое всегда предоставляла поисковая система, - это создавать ссылки естественным образом. Но мы все очень хорошо знаем, что идти по этому пути чрезвычайно трудно; особенно когда конкуренция идет очень хорошо с гораздо более сомнительной тактикой. Это не ошибка вашей SEO команды Большинство стартапов справляются со своей стратегией Как вы опередили их в SEO для позиции Google на странице 1?
Как вы опередили их в SEO для позиции Google на странице 1? Особенно, если они больше и их сайт старше, чем ваш. Я начинаю процесс SEO, глядя на то, что ваши конкуренты делают правильно. У них есть социальная сеть? Они ведут блог? Насколько актуален их контент и насколько хорошо они ссылаются на авторитетные страницы? Учитесь у своих конкурентов и смоделируйте свой собственный SEO, чтобы идти в ногу. Отставание означает выпадение из результатов поиска. Поскольку предметом
Так что же это означает для одностраничного SEO приложения?
Так какой предел?
Как долго Fetch будет ждать, пока Google будет ожидать таких типов асинхронных запросов, и когда она получит снимок вашего веб-сайта?
R§S, RẑS, R ° RêRẑRμ SEO?
Почему сайт вышел?
Вы ресторан одержимы?
Вы знаете кого-то, кто есть?
Как Google будет определять авторитетный и релевантный контент в 2020 году?
Какие показатели поведения пользователей может измерять Google в 2020 году?
Как могут результаты органического поиска отображаться в 2020 году и как они будут интегрироваться с платным поиском?


